Rozdělení řetězců v Looker Studio pomocí regulárních výrazů
Máme pro vás rychlý a praktický tip pro práci s Looker Studiem. V tomto textu budeme rozdělovat textové řetězce pomocí regulárních výrazů a budeme si hrát s vlastními dimenzemi.
Situace
Řekněme, že odesíláte z reklamní platformy v URL takovýto řetězec do vlastní dimenze v GA. Vypadá takto:
lineItem=USA~ACQ~AppNexus~PD~interscroller~D_M~lifestyle~35541382|bannerDomain=marieclaire.com.
Můžete odeslat jednotlivé hodnoty z dlouhého URL řetězce do GA jako vlastní dimenze. Je to jednodušší a rychlejší. Proč se tedy obtěžovat s rozpadáváním dlouhého stringu? Někdy si nemůžete dovolit luxus vlastnit GA 360 a ve verzi zdarma je vlastních dimenzí málo.
Chcete oddělit hodnoty lineItem a bannerDomain do dvou různých polí. Google Data Studio (nyní Looker Studio) poslouží jako vizualizační platforma. Tento oříšek rozlouskneme pomocí regulárních výrazů. Některé z vás napadne citát Jamieho Zawinského:
Když mají někteří lidé problém, řeknou si: „Jasně, že vím, jak na to. Použiji regulární výrazy.“ Nyní mají problémy dva.
Máte naprostou pravdu.
Řešení
Existuje mnoho způsobů, jak k tomuto problému přistupovat, ale já jsem využil tento.
1) Vytvoření dvou nových polí v Looker Studio
Jedno poslouží jako forma pro hodnotu Line Item a druhá pro hodnotu Banner Domain. To je ta snazší část.
2) Sestavení vzorců
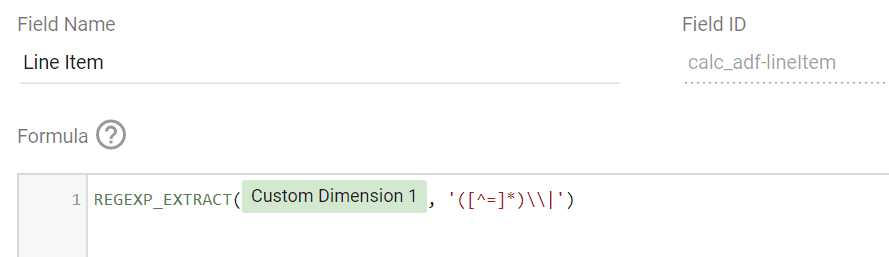
Začněme polem Line Item.
REGEXP_EXTRACT(Custom Dimension 1, '([^=]*)\\|')Tímto způsobem extrahujeme část řetězce mezi znaky „=“ a „|“. Je možné, že svislítko na konci extrahovaného řetězce zůstane součástí nového řetězce. Nebojte se, Looker Studio jej s největší pravděpodobností zahodí a nezobrazí v reportu.
Můžete si vyzkoušet funkčnost vzorce v nástroji regex101, který vám vřele doporučuji.
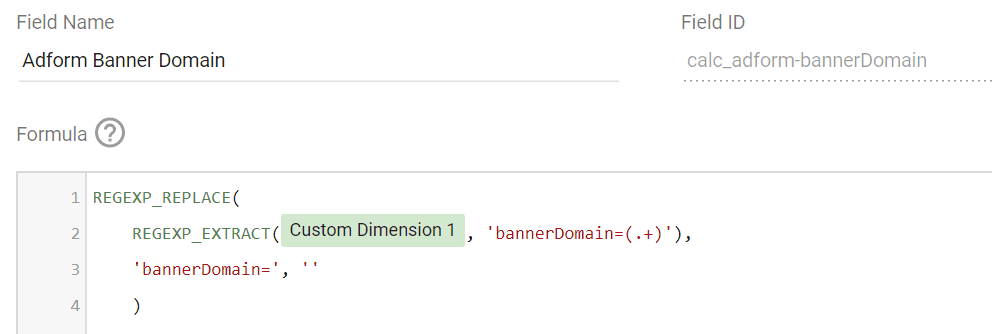
Pojďme k druhému vzorci, tentokrát pro pole Banner Domain. Zde je situace složitější, protože je třeba vyjmout zadní část řetězce. Nakonec jsem zvolil kombinaci regulárního výrazu a úprav v LS.
REGEXP_REPLACE(
REGEXP_EXTRACT(Custom Dimension 1, 'bannerDomain=(.+)'),
'bannerDomain=', ''
)Až příliš snadné, že? Vezmeme každý znak, který následuje po svislítku, včetně řetězce „bannerDomain=“. K tomu slouží funkce REGEXP_EXTRACT. Tento kód pak zabalíme do nahrazovací funkce REGEX_REPLACE, která najde řetězec „bannerDomain=“ a nahradí jej řetězcem stejně prázdným, jako je můj smysl života. Hotovo.
Zkontrolujte a otestujte svůj výraz znovu v nástroji regex101.
3) Vizualizace dat
Nyní můžete rozpadnout kampaně v reportu podle nově získaných dimenzí. Můžete tedy provádět další analýzy a pomoci svému PPC týmu mnohem efektivněji optimalizovat kampaně. Určitě z toho budou nadšení.
Upozornění
Možná jste si všimli, že v JavaScriptu stačí escapovat speciální znaky pomocí jednoduchého zpětného lomítka, ale v Looker Studiu musíte použít dvojité zpětné lomítko. To proto, že LS používá RE2 (ideální čtení před spaním).
Dalším problémem je, že pomocí funkce CASEnelze provádět složitější výpočty. Power BI nebo Tableau najednou vypadají čím dále tím lépe, že?
Příležitostně rozesíláme zpravodaj pro specialisty i manažery. Máte zájem?
Žádný spam, žádné otravné prodejní nabídky.

Ředitel
Honza Felt začal svou kariéru v PR agentuře, a postupně se díky sérii šťastných náhod dostal k analytice a kampaním. Nyní vede CF Agency. Nejraději řeší problémy, kde může uplatnit znalost marketingu v kombinaci s daty a reklamními technologiemi.



